Exploring Kyverno: Part 2, Mutation

Alright, here we go with another installment of the "Exploring Kyverno" series. Today I'm going to be looking at Kyverno's mutation ability, which is pretty cool in that it's one of the only admission controllers that has this capability. But if you haven't already, at least take the time to read the introduction so the stage is set.
Mutation is the ability take a request and tacitly alter it prior to it being stored in Kubernetes' data store. This is commonly done on new object creation requests so they conform to some existing standard. In this regard, mutation can be thought of as an alternative approach to a validation in enforce mode; rather than blocking a request which does not conform, it is altered so it does and the create therefore proceeds.
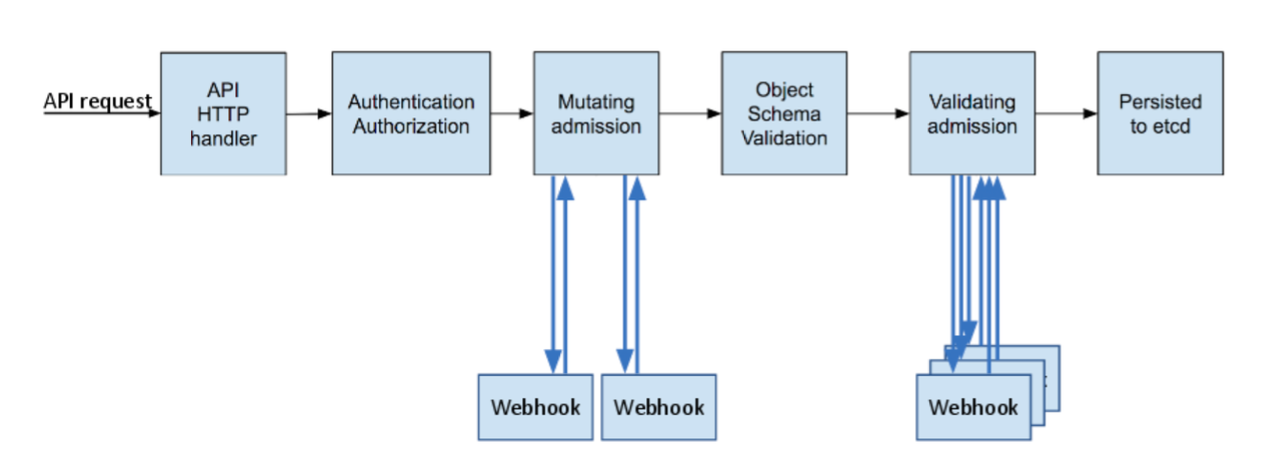
In Kubernetes, the two webhook types are mutating and validating. In a given workflow where admission controllers are invoked, the mutation happens prior to validation so that any validation rules can check the results of a mutation. This is illustrated in the below graphic borrowed from a Kubernetes blog on the subject.
With Kyverno, you can write a policy that applies these mutations based upon various criteria such as what should be mutated and how that should occur. Let's look at some practical examples.
1apiVersion: kyverno.io/v1
2kind: ClusterPolicy
3metadata:
4 name: label-namespaces
5spec:
6 background: false
7 rules:
8 - name: label-namespaces
9 match:
10 resources:
11 kinds:
12 - Namespace
13 mutate:
14 patchStrategicMerge:
15 metadata:
16 labels:
17 created-by: "{{request.userInfo.username}}"
Kyverno uses the patch strategic merge method of applying mutations, which is the same form used by kubectl when you edit or patch a resource. It gives a good amount of flexibility in deciding how alterations are to be performed.
In this example, we are assigning a label to every new Namespace object that gets created with a key of created-by and a value of the username who requested the creation. Similar to with validation rules in part one, we can use variables which, in this case, point to AdmissionReview data. Of course, we could have specified a static value, but this makes such labeling dynamic in nature.
Kyverno supports multiple mutation strategies presently, but either
patchStrategicMergeorpatchesJson6902is the one you should use from now forward.
So, rather than rejecting this request previously because the Namespace didn't have the label, we can add one very simply. On that point, what if we wanted to make a decision to mutate something based upon a condition? Using the previous example, we can elect to not add the created-by label if it already exists by using an add anchor. The only change would be the last line:
1+(created-by): "{{request.userInfo.username}}"
Written this way, if Kyverno sees this key it will leave it alone. Otherwise, it'll create it and set the value to the username as before. This is extremely useful when you want to control how resources get mutated but offer some choice.
Mutation rules, like validation rules, can apply to any kind of resource in your cluster and can lay down more complex objects based upon conditions. Let's look at another useful example where this is the case.
Typically with Deployments that have multiple replicas, you'd want them spread out as far and wide as possible to control failure domains. Kubernetes has Pod affinity abilities to make this happen. But sometimes developers may not know (or care) about this ability since it's more of an operational concern. Rather than fail those resources, what if you could just modify them so they conform to your availability standards for your cluster? With Kyverno you can, and it involves no code.
Check out this ClusterPolicy which searches for a label on your Deployments with the key of app and automatically injects the necessary Pod anti-affinity statement so the Pods within that Deployment are separated.
1apiVersion: kyverno.io/v1
2kind: ClusterPolicy
3metadata:
4 name: insert-podantiaffinity
5spec:
6 rules:
7 - name: insert-podantiaffinity
8 match:
9 resources:
10 kinds:
11 - Deployment
12 preconditions:
13 # This precondition ensures that the label `app` is applied to Pods
14 # within the Deployment resource and that it's not empty.
15 - key: "{{request.object.metadata.labels.app}}"
16 operator: NotEquals
17 value: ""
18 mutate:
19 patchStrategicMerge:
20 spec:
21 template:
22 spec:
23 # Add the `affinity` key and others if not already specified in the Deployment manifest.
24 +(affinity):
25 +(podAntiAffinity):
26 +(preferredDuringSchedulingIgnoredDuringExecution):
27 - weight: 1
28 podAffinityTerm:
29 topologyKey: "kubernetes.io/hostname"
30 labelSelector:
31 matchExpressions:
32 - key: app
33 operator: In
34 values:
35 - "{{request.object.metadata.labels.app}}"
The above policy can be read as, "Check all Deployments that have something in their app label and assign the podAntiAffinity ability based on the kubernetes.io/hostname key but ONLY if it isn't specified in the Deployment spec." Although I didn't cover it in the validation article in part one, this policy uses a concept called preconditions which is a way for Kyverno to more effeciently filter out the match candidates. Here it's just ensuring that app isn't empty.
Let's try this out for real and see what happens.
Take this sample Deployment manifest:
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 labels:
5 app: busybox
6 name: busybox
7spec:
8 replicas: 3
9 selector:
10 matchLabels:
11 app: busybox
12 template:
13 metadata:
14 labels:
15 app: busybox
16 spec:
17 automountServiceAccountToken: false
18 containers:
19 - image: busybox:1.28
20 name: busybox
21 command: ["sleep", "9999"]
You'll notice it's a plain jane Deployment object. Just a busybox Pod taking a nap, and three replicas at that.
Here are the nodes in my system:
1$ k get no
2NAME STATUS ROLES AGE VERSION
3cztkg01-control-plane-fg9zs Ready master 6d6h v1.19.1+vmware.2
4cztkg01-md-0-b4b9cf9ff-25pmt Ready <none> 6d6h v1.19.1+vmware.2
5cztkg01-md-0-b4b9cf9ff-pj99h Ready <none> 6d6h v1.19.1+vmware.2
6cztkg01-md-0-b4b9cf9ff-sgq99 Ready <none> 6d6h v1.19.1+vmware.2
Fairly simple; one control plane and three workers.
Now, create the ClusterPolicy from the sample above. Once that's there, create the Deployment from the manifest.
Let's check out the Pod distribution:
1$ k get po -o wide
2NAME READY STATUS RESTARTS AGE IP NODE
3busybox-c7f857879-hs6nd 1/1 Running 0 5m34s 100.96.1.20 cztkg01-md-0-b4b9cf9ff-sgq99
4busybox-c7f857879-ljd9f 1/1 Running 0 5m34s 100.96.3.80 cztkg01-md-0-b4b9cf9ff-pj99h
5busybox-c7f857879-ndj7m 1/1 Running 0 5m34s 100.96.2.8 cztkg01-md-0-b4b9cf9ff-25pmt
We can see they're distributed across each of the three workers. Let's inspect this Deployment object to see if Kyverno really did mutate it or if it's luck (I'm not bombarding you with the entire YAML output).
1 spec:
2 affinity:
3 podAntiAffinity:
4 preferredDuringSchedulingIgnoredDuringExecution:
5 - podAffinityTerm:
6 labelSelector:
7 matchExpressions:
8 - key: app
9 operator: In
10 values:
11 - busybox
12 topologyKey: kubernetes.io/hostname
13 weight: 1
Here you can clearly see it has inserted the affinity object and set the value to app according to our label in this case. This can be super valuable in easily distributing your replicas in your environment. And a hidden benefit mutation policies from Kyverno can have is that they keep your manifests simpler and therefore less to author and break, even if you previously did something like this at the Kustomize stage or similar.
Ok, let's do one more, and something even more complex.
Sometimes you might have multiple levels of mutations you need to apply, similar to a script with multiple processing steps but that are dependent upon inputs. So for example with mutations, you might have multiple levels of mutation rules apply to incoming resources. The match statement in rule A would apply a mutation to the resource, and the result of that mutation would trigger a match statement in rule B that would apply a second mutation. Kyverno can do this with cascading mutations.
For example, let's say you needed to assign a label to each incoming Pod describing the type of application it contained. For those with an image having the string either cassandra or mongo you wished to apply the label type=database. This could be done with the following sample policy.
1apiVersion: kyverno.io/v1
2kind: ClusterPolicy
3metadata:
4 name: database-type-labeling
5spec:
6 rules:
7 - name: assign-type-database
8 match:
9 resources:
10 kinds:
11 - Pod
12 mutate:
13 patchStrategicMerge:
14 metadata:
15 labels:
16 type: database
17 spec:
18 (containers):
19 - (image): "*cassandra* | *mongo*"
Also assume that for certain application types, a backup strategy needs to be defined. For those applications where type=database, this would be designated with an additional label with the key name of backup-needed and value of either yes or no. The label would only be added if not already specified since operators can choose if they want protection or not. This policy would be defined like the following.
1apiVersion: kyverno.io/v1
2kind: ClusterPolicy
3metadata:
4 name: database-backup-labeling
5spec:
6 rules:
7 - name: assign-backup-database
8 match:
9 resources:
10 kinds:
11 - Pod
12 selector:
13 matchLabels:
14 type: database
15 mutate:
16 patchStrategicMerge:
17 metadata:
18 labels:
19 +(backup-needed): "yes"
In such a case, Kyverno is able to perform cascading mutations whereby an incoming Pod that matched in the first rule and was mutated would potentially be further mutated by the second rule. In these cases, the rules must be ordered from top to bottom in the order of their dependencies and stored within the same policy. The resulting policy definition would look like the following:
1apiVersion: kyverno.io/v1
2kind: ClusterPolicy
3metadata:
4 name: database-protection
5spec:
6 rules:
7 - name: assign-type-database
8 match:
9 resources:
10 kinds:
11 - Pod
12 mutate:
13 patchStrategicMerge:
14 metadata:
15 labels:
16 type: database
17 spec:
18 (containers):
19 - (image): "*cassandra* | *mongo*"
20 - name: assign-backup-database
21 match:
22 resources:
23 kinds:
24 - Pod
25 selector:
26 matchLabels:
27 type: database
28 mutate:
29 patchStrategicMerge:
30 metadata:
31 labels:
32 +(backup-needed): yes
Cool. So let's test this policy out by creating a Cassandra Pod.
1$ k run cassandra --image=cassandra:latest
2pod/cassandra created
Check out the labels.
1$ k get po --show-labels -l app=cassandra
2NAME READY STATUS RESTARTS AGE LABELS
3cassandra 1/1 Running 0 42s backup-needed=yes,run=cassandra,type=database
Awesome. So it assigned both labels, the type based on the first mutation, and then backup-needed in the second only because it met the criteria of the results of the first.
Now let's test it by specifying our own value of backup-needed setting no to see if we get the same result.
1k run cassandra --image=cassandra:latest --labels backup-needed=no
Inspect the Pod once again.
1$ k get po --show-labels -l app=cassandra
2NAME READY STATUS RESTARTS AGE LABELS
3cassandra 1/1 Running 0 42s backup-needed=no,run=cassandra,type=database
Ah, so in this last test, the first mutation still applied but not the second.
Hopefully you can see how powerful these mutations can be. Not only can you make these changes under the covers, but it doesn't require you to write any code to do so!
By the way, as of this writing, OPA/Gatekeeper has no mutation ability. So even if you were amenable to the idea of writing a programming language to mutate resources, you couldn't do it right now.
Alright, that's it for mutation. I hope you found this interesting, practical, and makes you want to go out and get some policy in your Kubernetes environment now. Check back for the third installment of this series as I cover the generation capabilities of Kyverno!