New Orchestrated Restarts in vSphere 6.5

vSphere 6.5 was released at the end of 2016 and so, at this point, has been on the market for about a year. VMware introduced several new features in vSphere 6.5, and several of them are very, very useful however sometimes people don’t take the time to really read and understand these new features to solve problems that might already exist. One such feature that I’d like to focus on today is the new HA feature called Orchestrated Restarts. In prior releases, vSphere High Availability (HA) has served to reliably restart VMs on available hosts should one host fail. It does this by building a manifest of protected VMs and, through a master-slave relationship structure, makes those manifests known to other cluster members. Fun fact that I’ve used in interviews when assessing another’s VMware skill set is HA does not require vCenter for its operation although it does for the setup. In other words, HA is able to restart VMs from a failed host even if vCenter is unavailable for any reason. The gap with HA, until vSphere 6.5 that is, is it has no knowledge of the VMs it is restarting as far as their interdependencies are concerned. So, in some situations, HA may restart a VM that has a dependency upon another VM which results in application unavailability when all return to service. In vSphere 6.5, VMware addressed this need with a new enhancement to HA called Orchestrated Restarts in which you can declare those dependencies and their order so HA restarts VMs in the necessary sequence. This feature is imminently useful in multi-tier applications, and one such application that can benefit tremendously is vRealize Automation. In this article, I’ll walk through this feature and illustrate how you can leverage it to increase availability of vRA in the face of disaster in addition to covering a couple other best practices with vSphere features when dealing with similar stacks.
In prior versions of HA, there was no dependency awareness—HA just restarted any and all VMs it knew about in any order. The focus was on making them power on and that’s it. There were (and still are) restart priorities which can be set, but not a chain. In vSphere 6.5, this changed with Orchestrated Restarts.
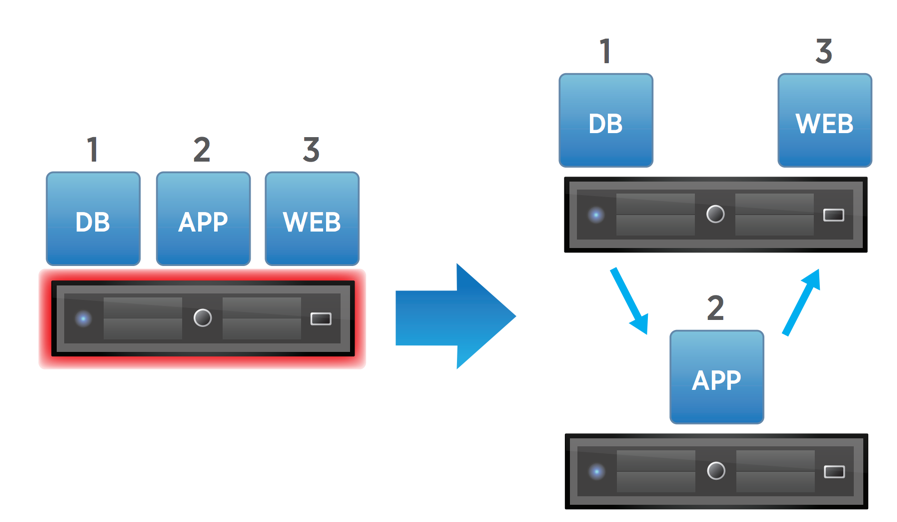
With special rules set in the web client, we can determine the order in which power-ons should occur. First, let’s look at a common vRA architecture. These are the machines present.

We’ve got a couple front-end servers (App), manager and web roles (IaaS), a vSphere Agent server (Agent), and a couple of DEM workers (DEM). The front-end servers have to be available before anything else is, followed by IaaS, and then the rest. So, effectively, we have a 3-tier structure.
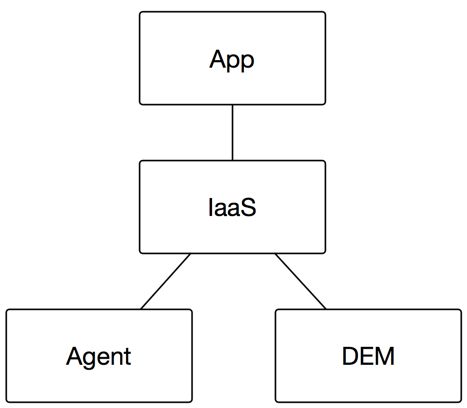
And the dependencies are in this order, so therefore App must be available before IaaS, and IaaS must be available before Agent or DEM.
Going back over to vCenter, we have to first create our groups or tiers. From the Hosts and Clusters view, click the cluster object, then Configure, and go down to VM/Host Groups.

We’ll add a new group and put the App servers in them.
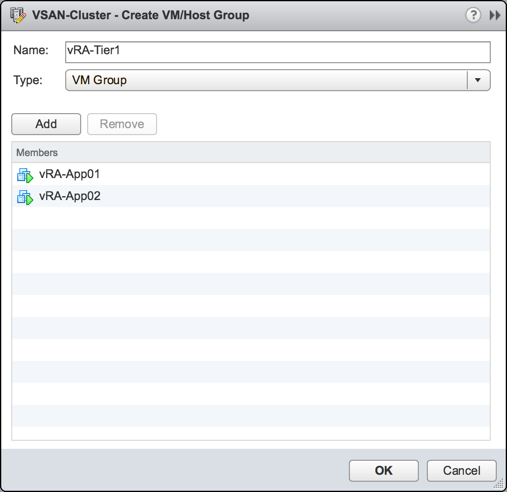
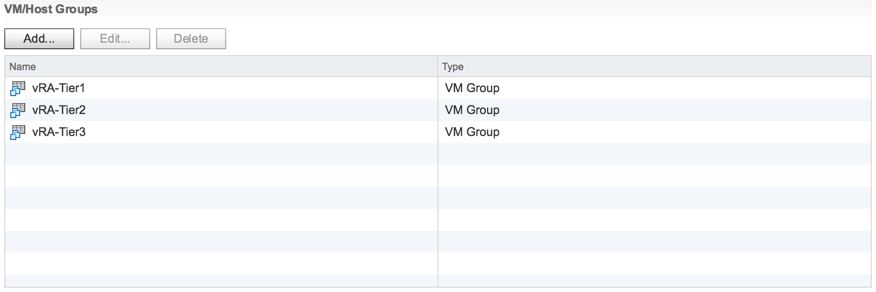
And do the same for the other tiers with the third tier having three VMs. It should end up looking like the following.
Now that you have those tiers, go down to VM/Host Rules beneath it. Here is where the new feature resides. In the past, there was just affinity, anti-affinity, and host pinning. In 6.5, there is an additional option now called “Virtual Machines to Virtual Machines.”
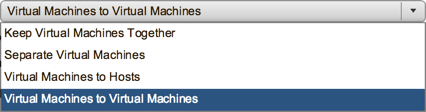
This is the rule type we want to leverage, so we’ll create a new rule based on this and select the first two tiers.
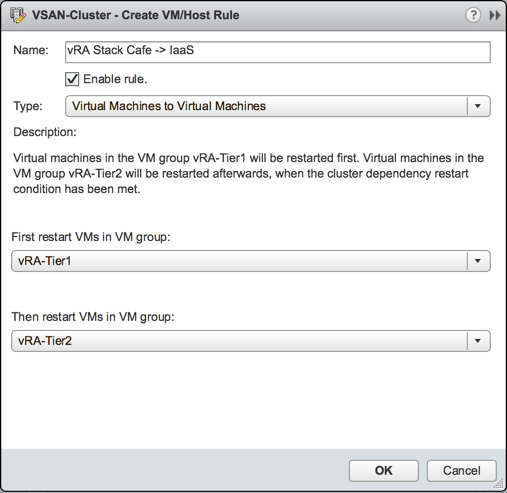
This rule says anything in vRA-Tier1 must be restarted before anything in vRA-Tier2 in the case where a host failure takes out members from both groups. Now we repeat the process for tiers 2 and 3. Once complete, you should have at least two rules in place, possibly more if you’re following these instructions for another application.

After they’ve been saved, you should see tasks that kick off that indicate these rules are being populated on the underlying ESXi hosts.
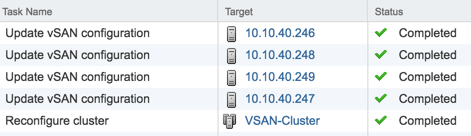
In my case, I’m running vSAN and since vSAN and HA are very closely coupled, the HA rules serve as vSAN cluster updates as well. And by the way, here is another opportunity we have to exercise best practice with a distributed or enterprise vRealize Automation stack. We need to ensure machines of like tier are separated to increase availability. This is also done here and we need to specify some anti-affinity rules to keep the App servers apart as well as the IaaS servers and others. My full complement of rules, both group dependency based and anti-affinity, looks like so.
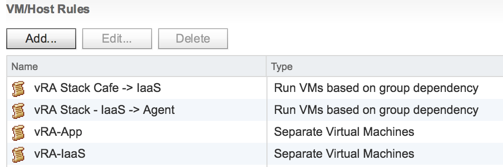
Now we have the VM groups and the orchestration rules, let’s configure a couple other important points to make this stack function better. In vRA, the front-end (café) appliance(s) usually take some time to boot up because of the number of services that are involved. This process, even with a well-performing infrastructure can still take several minutes to complete, so we should complement these orchestrated restart rules with a delay that’ll properly allow the front-end to start up before attempting to start other tiers. After all, there’s no point starting other tiers if they have to be restarted manually later because the first tier isn’t yet ready for action.
Let’s go down to VM Overrides and add a couple rules. This is something else that’s great about vSphere 6.5, the ability to fine-tune how HA restarts VMs based on conditions. Add a new rule and put both App servers in there.
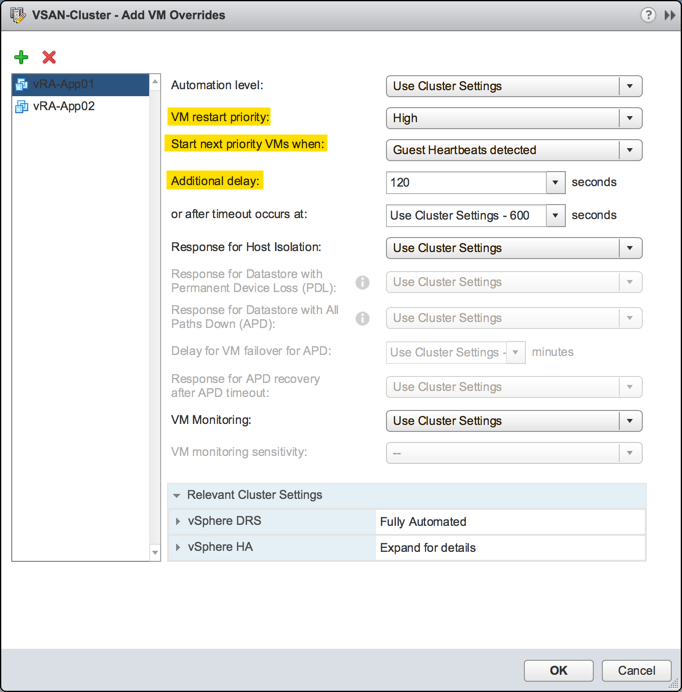
Three key things we want to change. First, the VM restart priority. By default, an HA cluster has a Medium restart priority where everything is of equal weight. We want to change the front-end appliances to be a bit higher than that because this serves as the login portal, so HA needs to make haste when prioritizing resources to start VMs elsewhere. Next, the “start next priority VMs when” setting allows us to instruct HA when to being starting VMs in the next rule. There are a few options here.
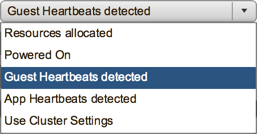
The default in the cluster unless it’s overridden is “Resources allocated” which simply means as soon as the scheduler has powered it on—basically immediately. Powered On is waiting for confirmation that the VM was actually powered on rather than just attempted. But the one that’s extremely helpful here is what I’d suggest setting which is “Guest Heartbeats detected.” This setting allows ESXi to listen for heartbeats from VMware tools, which is usually a good indicator that the VM in question has reached a suitable run state for its applications to initialize.
Then back to the list, an additional delay of 120 seconds will further allow the front-end to let services start before attempting to start any IaaS servers. If, after this custom value, guest heartbeats are still not detected, a timeout will occur and, afterwards, other VMs will be started. Extremely helpful in these situations when you need all members to come up, even at the expense of pieces maybe needing to be rebooted again. Rinse and repeat for your second tier containing your IaaS layer. Using the same settings as the front-end tier is just fine.
Great! Now the only thing left is to test. I’ll kill a host in my lab to see what happens. Obviously, you may not want to do this in a production situation :)
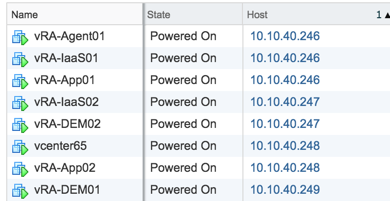
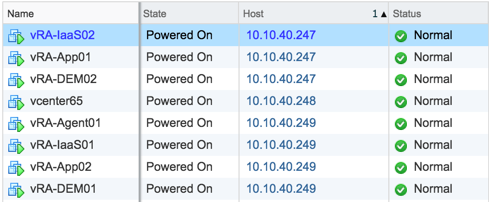
I killed the first host (10.10.40.246) at 7:55pm that was running App01, IaaS01, and Agent01. Here’s the state before.
Now after the host has died and vCenter acknowledges that, the membership looks like the following.
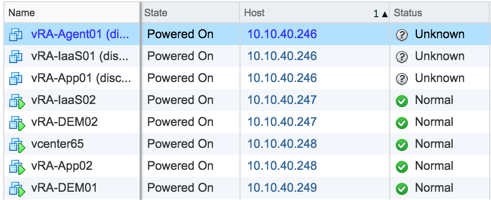
Those VMs show disconnected with an unknown status. Let’s see how HA behaves.

Ok, good, so at 8:00pm it started up App01 as it should have once vSAN updated its cluster status. Normally this failover is a bit quicker when not using vSAN.
Next, when guest heartbeats were detected, the 2-minute countdown started.

So at 8:04, it then started up IaaS01 followed by Agent01 similarly. After a few minutes, the stack is back up and functional.
Pretty great enhancements in vSphere 6.5 related to availability if you ask me, and all these features are extremely handy when running vRA on top.
I hope this has been a useful illustration on a couple of the new features in vSphere 6.5 and how you can leverage those to provide even greater availability to vRealize Automation. Go forward and use these features anywhere you have application dependencies, and if you aren’t on vSphere 6.5 yet, start planning for it now!