Preserving Authorship in a GitOps World with Kyverno
It seems just about everyone is doing GitOps in Kubernetes these days. With so many available tools and the maturity of them, it's hard to avoid it. But with only one tool being responsible for the actual creation in the cluster of the resources stored in git, it makes it difficult or impossible for someone to answer the question, "who is the author of this thing?" In this post, I'll show one nifty method for getting more mileage out of Kyverno by using its CLI to help you answer this question in an automated fashion.
One of the inevitabilities of Kubernetes--or, indeed, any IT system--is that once it proves to be successful, more people within an organization begin to adopt it. More people equals more hands in the pie as it were, and being able to identify those people is often times quite important. From an organizational perspective, people are grouped into teams and it's a well-known and commonly-accepted practice for things like team names to be required, often as labels or annotations, when creating Kubernetes resources. This desire falls under the governance category when it comes to policy and Kyverno handles this extremely easily today with validate rules. Teams are often necessary, but it still doesn't capture the individual person. Which person on this team was responsible here? When multiple people participate in authoring resources into a single git repo, things get tricky.
Assigning owners automatically is also possible today as shown in this mutate policy. In cases where users are allowed to individually and directly create resources against a cluster, this can be a viable approach. But in the GitOps world, this isn't how things happen. The tool of choice (Argo CD, Flux, etc) is the sole creator of these resources and so using this policy would result in indicating all resources were created by the same ServiceAccount like shown below in a snippet of a Pod being deployed to a cluster by Argo CD.
1apiVersion: v1
2kind: Pod
3metadata:
4 annotations:
5 kyverno.io/created-by: '{"username":"system:serviceaccount:argocd:argocd-application-controller"}'
6 creationTimestamp: "2023-02-12T15:51:27Z"
7 generation: 1
8 labels:
9 app.kubernetes.io/instance: signed-development
10 name: nginx-platform
11 namespace: platform-a
12 resourceVersion: "1750857"
13 uid: ad2b0ce9-1b6e-47ed-a9d2-946c7856c179
14spec:
15 <snip>
The resulting workflow this represents looks like the below.
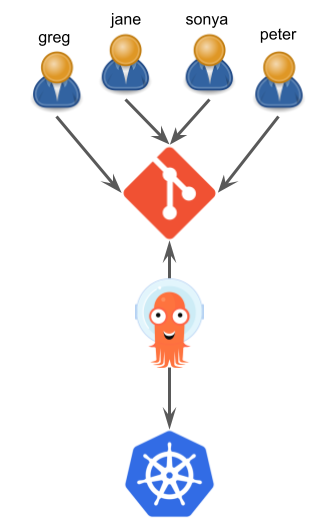
Even though the ServiceAccount named, in this case, argocd-application-controller was the principal responsible for the creation of the resource, it wasn't the author. What's needed here is an automated way to add this authorship information inside of the pipeline to the resources being created by their human operators.
The Kyverno CLI has a wide range of functionalities. One of its capabilities is being able to apply a Kubernetes resource manifest to a policy and view the result. This works not just for validate rules but for mutate rules as well. When used with a mutate rule, it can also show the final result of that mutation. This result can very easily be sent to a file by using the -o flag.
See the output of the
kyverno apply -hcommand for all the possibilities.
Kyverno also has a rich variable system and has the ability to set the values of those variables during runtime in the CLI. A mutate rule with a variable can be written to add a label or annotation to any Kubernetes resource quite simply. In this example, I've chosen a label named corp.org/author. The value of this will be dynamically set in the next step.
1apiVersion: kyverno.io/v1
2kind: ClusterPolicy
3metadata:
4 name: add-labels
5spec:
6 background: false
7 rules:
8 - name: add-author
9 match:
10 any:
11 - resources:
12 kinds:
13 - "*"
14 mutate:
15 patchStrategicMerge:
16 metadata:
17 labels:
18 corp.org/author: "{{request.githubprauthor}}"
If you're already familiar with Kyverno and its CLI, the "trick" you might have noticed here is using a variable in the policy which begins with
request.. Although variables which begin with this word normally come from the Kubernetes API server via its AdmissionReview, I'm piggybacking off of that to define my own. This obviously would never work in a live cluster, but it allows the CLI to permit the variable rather than flagging it as unrecognizable.
Basically all of the CI tools out there have some type of pre-defined variable which captures the ID of the user who initiated a pull/merge request. In GitHub Actions, which is where I'll be showing this, it's found under the event type at github.event.pull_request.user.login. We should then be able to pair a mutate rule, like the above, with this information to capture the ID of that user at the time such a request is opened. Once pieced together, we can do something like the example GitHub Actions workflow shown below. Let's break it down.
- A user writes their manifests into the
/incomingdirectory. - When a PR is submitted, all your normal workflows fire. This is where you could validate those resources and fail or return messages allowing the user to correct them as needed.
- When the PR is merged, the workflow uses the Kyverno CLI to mutate each of the manifests in
/incomingadding the user responsible for the PR as the value of thecorp.org/authorlabel. - The mutated manifests are sent to the
/outgoingdirectory and the/incomingdirectory is scrubbed clean. - Your GitOps tool of choice is configured to look at the
/outgoingdirectory and deploy whatever is inside. - Once a new manifest has been committed, your tool then deploys those changes to your cluster.
1name: Merge workflow
2
3# only trigger on pull request closed events
4on:
5 pull_request:
6 types: [ closed ]
7env:
8 VERSION: v1.9.0
9
10jobs:
11 merge_job:
12 # this job will only run if the PR has been merged
13 if: github.event.pull_request.merged == true
14 runs-on: ubuntu-latest
15 permissions:
16 contents: write
17 actions: read
18 id-token: write
19 steps:
20 - name: Checkout
21 uses: actions/checkout@v3
22 with:
23 fetch-depth: 0
24 - name: Write author
25 run: |
26 curl -sLO https://github.com/kyverno/kyverno/releases/download/${{ env.VERSION }}/kyverno-cli_${{ env.VERSION }}_linux_x86_64.tar.gz
27 tar -xf kyverno-cli_${{ env.VERSION }}_linux_x86_64.tar.gz
28 ./kyverno version
29 for f in $(ls ./incoming)
30 do
31 if [[ "$f" = *\.yaml ]]
32 then
33 echo "Adding authorship to incoming/$f"
34 ./kyverno apply author.yaml -r incoming/$f --set request.githubprauthor=${{github.event.pull_request.user.login}} -o outgoing/temp.yaml
35 sed '/^[[:space:]]*$/d' outgoing/temp.yaml > outgoing/$f
36 rm incoming/$f
37 rm outgoing/temp.yaml
38 fi
39 done
40 - name: Push manifests
41 uses: EndBug/add-and-commit@v9
42 with:
43 author_name: GitHub Actions
44 commit: --signoff
45 default_author: github_actions
46 message: 'Manifests committed.'
After this flow completes and your GitOps tool deploys the resources, you should now be able to very easily and conveniently see who the original author of that resource was. Below you can tell by the value of corp.org/author that my GitHub account ("chipzoller") was used to author this resource irrespective of the GitOps tool used to actually deploy it.
1$ kubectl get deploy product-bravo -o yaml
2
3apiVersion: apps/v1
4kind: Deployment
5metadata:
6 annotations:
7 deployment.kubernetes.io/revision: "1"
8 kubectl.kubernetes.io/last-applied-configuration: |
9 {"apiVersion":"apps/v1","kind":"Deployment","metadata":{"annotations":{},"labels":{"app.kubernetes.io/instance":"crest","corp.org/author":"chipzoller"},"name":"product-bravo","namespace":"default"},"spec":{"replicas":1,"selector":{"matchLabels":{"app":"prodb"}},"template":{"metadata":{"labels":{"app":"prodb"}},"spec":{"containers":[{"args":["sleep","1d"],"image":"busybox:1.28","name":"busybox"}]}}}}
10 creationTimestamp: "2023-02-12T18:49:11Z"
11 generation: 1
12 labels:
13 app.kubernetes.io/instance: crest
14 corp.org/author: chipzoller
15 name: product-bravo
16 namespace: default
17 resourceVersion: "1769507"
18 uid: 7779e7f9-0a95-477b-9098-3758c5330e80
19spec:
20 progressDeadlineSeconds: 600
21 replicas: 1
22 revisionHistoryLimit: 10
23 selector:
24 matchLabels:
25 app: prodb
26 strategy:
27 rollingUpdate:
28 maxSurge: 25%
29 maxUnavailable: 25%
30 type: RollingUpdate
31 template:
32 metadata:
33 creationTimestamp: null
34 labels:
35 app: prodb
36 spec:
37 containers:
38 - args:
39 - sleep
40 - 1d
41 image: busybox:1.28
42 imagePullPolicy: IfNotPresent
43 name: busybox
44 resources: {}
45 terminationMessagePath: /dev/termination-log
46 terminationMessagePolicy: File
47 dnsPolicy: ClusterFirst
48 restartPolicy: Always
49 schedulerName: default-scheduler
50 securityContext: {}
51 terminationGracePeriodSeconds: 30
52status:
53 availableReplicas: 1
54 conditions:
55 - lastTransitionTime: "2023-02-12T18:49:13Z"
56 lastUpdateTime: "2023-02-12T18:49:13Z"
57 message: Deployment has minimum availability.
58 reason: MinimumReplicasAvailable
59 status: "True"
60 type: Available
61 - lastTransitionTime: "2023-02-12T18:49:11Z"
62 lastUpdateTime: "2023-02-12T18:49:13Z"
63 message: ReplicaSet "product-bravo-84fc4998bd" has successfully progressed.
64 reason: NewReplicaSetAvailable
65 status: "True"
66 type: Progressing
67 observedGeneration: 1
68 readyReplicas: 1
69 replicas: 1
70 updatedReplicas: 1
This technique can be used to further enhance these manifests with even more information about the individuals involved in the authoring or approval process. For example, you might also want to know the pull request from which this particular resource manifest originated, or the account responsible for merging it. You can add this information as additional labels and pass these as variables to the Kyverno CLI referencing the appropriate context variables.
1 mutate:
2 patchStrategicMerge:
3 metadata:
4 labels:
5 corp.org/author: "{{request.githubprauthor}}"
6 corp.org/pr: "{{request.githubpr | to_string(@) }}"
7 corp.org/merger: "{{request.githubmerger}}"
1--set request.githubprauthor=${{github.event.pull_request.user.login}},\
2request.githubpr=${{github.event.number}},\
3request.githubmerger=${{github.event.pull_request.merged_by.login}}
1apiVersion: v1
2kind: Namespace
3metadata:
4 labels:
5 corp.org/author: realshuting
6 corp.org/merger: chipzoller
7 corp.org/pr: "13"
8 name: org-ns-bar
And that's basically it. Not a super complex bit of automation but nevertheless can assist in the process of following back to its source any given resource that's deployed into your Kubernetes environments. This method works with any GitOps tool you want and on basically any CI tool you wish to use.
If you liked this post, I'm always glad to hear feedback so feel free to drop me a note on Twitter or come find me on Slack.