Reducing Pod Volume Update Times
There was an interesting poll I happened to stumble across on Twitter the other day from Ahmet Alp Balkan, a former staff software engineer and tech lead at Twitter's Kubernetes-based compute infrastructure team. Although I don't know Ahmet personally, I know him through his work on the popular (and terrific) krew as well as kubectx, both of which are used by Kubernetes users everywhere, myself included. Before going any further in this article, I want to give a wholehearted THANK YOU to Ahmet as well as those who participated in the authoring and improvement of those tools. You have not only saved endless hours of toil but made working with Kubernetes so much better.
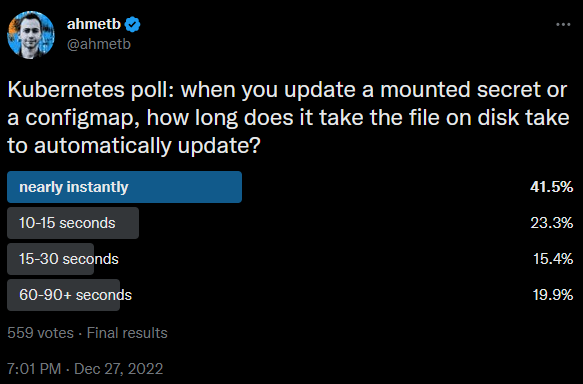
Although I didn't vote, I was one of the 41.5% who guessed that it was "nearly instantly". I then saw Ahmet follow up with a very interesting blog post a day later entitled Why Kubernetes secrets take so long to update? where I learned that I, and the rest of the near 42% of respondents, were wrong. The actual time it takes to fully propagate changes made to downstream Pods is more like 60-90 seconds. I thought this was extremely interesting and, sure enough, that's about how long it took for me in numerous tests I conducted.
What really piqued my interest, and why I'm writing about someone else's post, was this snippet:
Due to the lack of a notification channel, the secret/configMap volumes are only updated is when pod is "synced" in the syncPod function which gets called under these circumstances:
- something about the pod changes (pod event, update to Pod object on the API, containe[r] lifecycle change on the container runtime)–which do not happen very often while the pod is running, and
- periodically, roughly every minute or so.
Very interesting! He then went on to state:
Can we make the updates go out faster? It turns out, yes. Remember the #1 bullet point above? What if we trigger some change to the Pod status to generate an event to get our pod to the "pod sync loop" quicker?
For example, if you modify Pod object annotations on the API, it won’t restart the Pod, but it will immediately add the Pod to the reconciliation queue. Then, the secret volume will be immediately re-calculated and the change will be picked up in less than a second. (But as you can imagine, updating annotations is not practical, as most users don't manage Pod objects directly.)
Cool! So what if we could make updating such annotations on a Pod be practical? Is this something that's possible? This is what got my gears turning and so I set out to see if this could possibly be yet another job for Kyverno, a tool which seems to have almost no end to its practical use in Kubernetes.
TL;DR: YES! I found not only was this possible but simple and can be done in a declarative fashion using policy as code. After getting a proof-of-concept going, it reduced the refresh time from that 60-90 seconds to about 1-2 seconds end-to-end. Let me show you how to do this!
You'll need Kyverno 1.7 or better to take advantage of its super cool "mutate existing" rule capabilities, which is something I haven't seen in any other policy engine. This allows you to do two things: 1) retroactively mutate existing (as opposed to "new") resources and 2) allow you to mutate a resource which is different than another resource which may serve as the trigger. Because what we need in a solution here is to watch when a given ConfigMap or Secret is updated and then take action on a Pod which consumes it. The action we can take is to annotate the Pod which should cause kubelet to refresh the volume mount.
Note that you'll need to grant Kyverno additional privileges to update Pods here since this isn't something it ships with by default. If you're on 1.8+, you can use this handy ClusterRole which will aggregate to the kyverno ClusterRole without having to hand edit anything.
1apiVersion: rbac.authorization.k8s.io/v1
2kind: ClusterRole
3metadata:
4 labels:
5 app: kyverno
6 app.kubernetes.io/instance: kyverno
7 app.kubernetes.io/name: kyverno
8 name: kyverno:update-pods
9rules:
10- apiGroups:
11 - ""
12 resources:
13 - pods
14 verbs:
15 - update
Here's the Kyverno policy that will get the job done.
1apiVersion: kyverno.io/v1
2kind: ClusterPolicy
3metadata:
4 name: reload-configmaps
5spec:
6 mutateExistingOnPolicyUpdate: false
7 rules:
8 - name: trigger-annotation
9 match:
10 any:
11 - resources:
12 kinds:
13 - ConfigMap ### Watch for only ConfigMaps here but it can be anything
14 names:
15 - mycm ### Watch the ConfigMap named `mycm` specifically
16 preconditions:
17 all:
18 - key: "{{ request.operation }}" ### We only care about UPDATEs to those ConfigMaps so we filter out everything else
19 operator: Equals
20 value: UPDATE
21 mutate:
22 targets:
23 - apiVersion: v1
24 kind: Pod
25 namespace: "{{ request.namespace }}" ### Since the ConfigMap is Namespaced, we know the Pod(s) we need to update are in that same Namespace
26 patchStrategicMerge:
27 metadata:
28 annotations:
29 corp.org/random: "{{ random('[0-9a-z]{8}') }}" ### Write some random string that's eight characters long comprised of numbers and lower-case letters
30 spec:
31 volumes:
32 - configMap:
33 <(name): mycm ### Only write that annotation if the Pod is mounting the ConfigMap `mycm` as a volume
Let's see this in action!
Once you've gotten Kyverno installed and running, create a Namespace called foo or whatever and some test ConfigMap we'll consume in a volume. You can see the one below is all labeled and ready to go.
1apiVersion: v1
2data:
3 fookey: myspecialvalue
4kind: ConfigMap
5metadata:
6 name: mycm
7 namespace: foo
Let's create a simple Pod to reference this and establish a baseline. The mypod below will mount the mycm ConfigMap at /etc/mycm.
1apiVersion: v1
2kind: Pod
3metadata:
4 name: mypod
5 namespace: foo
6spec:
7 containers:
8 - name: busybox
9 image: busybox:1.35
10 command: ["sleep", "1d"]
11 volumeMounts:
12 - name: mycm
13 mountPath: /etc/mycm
14 volumes:
15 - name: mycm
16 configMap:
17 name: mycm
We should be able to exec into this Pod and confirm that the contents of the ConfigMap are visible.
1$ k -n foo exec mypod -- cat /etc/mycm/fookey
2myspecialvalue
Without installing the policy from earlier, let's test about how long it takes for an update to that ConfigMap to be reflected in the Pod. Make some modification to the value of fookey and let's apply and watch the Pod.
1kubectl apply -f mycm.yaml && watch -n 1 kubectl -n foo exec mypod -- cat /etc/mycm/fookey
Although there are more bash-savvy ways to get an exact measurement, just by counting you should see it may take anywhere from 30-90 seconds for that new value to get picked up.
Now create the ClusterPolicy from above and re-run the test. When you update the ConfigMap, it will trigger Kyverno into action. It will see the UPDATE to that ConfigMap, find the Pods in the same Namespace which mount it by that name, and write/update the annotation corp.org/random with some random value it generates, thereby forcing a refresh on the contents of the volume. It should only take between 1-2 seconds from the time the upstream ConfigMap is updated to the time the downstream Pod(s) can access the new contents.
After finishing this up, I suddenly remembered that I had written about something very similar here back in September. The main difference between these two approaches is the reloading article requires (and performs), due to the Secret being consumed in an environment variable, a new rollout on a Deployment while the method outlined here does not. You can couple this approach with the syncing approach to have lightning quick reloading AND only have to update one reference ConfigMap or Secret. That's pretty nice!
This could be a very handy approach when you need low latency between when an update to a reference ConfigMap/Secret occurs and the time when it gets made available to workloads. Thank you to Ahmet for the insight and for inspiring me to figure this use case out!