Kyverno: The Swiss Army Knife of Kubernetes

With all software there is an inflection point where its domain ends and yours beings. Software such as Kubernetes provides an awesome cloud-native platform which gives you common tools to solve common problems, but like all it has its limits. When your needs extend outside those limits, it's time to start hunting for another solution. With Kubernetes, it's basically a foregone conclusion that you will be involving other solutions. The end result can (and often will) result in a toolbox full of purpose-built tools for those corner cases. But that's problematic in a number of ways. Things get complicated. You don't have a uniform way of accomplishing your tasks since each is with a separate tool, and in turn this means your technical debt grows. Since I've been working with Kyverno, a Kubernetes-native policy engine, I've seen LOTS of this firsthand in users' environments. And although I wrote a series on this tool last month covering each of its three main pieces of functionality, I didn't really cover how Kyverno can be a replacement for those bespoke tools. In this article, I'm going to lay out some common and real-life Kubernetes use cases seen in the wild which would otherwise necessitate a separate, specialized tool but instead can all be replaced by Kyverno, the Swiss Army knife of Kubernetes. I'm anxious to share these with you, so let's get started.
If you're reading this and don't have any idea what Kyverno is, I'd highly recommend at least checking out the intro article in my Exploring Kyverno series for some background. Kyverno, a CNCF sandbox project, just celebrated its first release since joining the CNCF, and v1.3.0 is a major one at that containing over 90 fixes and enhancements.
Resource Annotater
Metadata is king no matter what the platform. And within Kubernetes, this metadata is a hugely important source of not only useful information to humans but directives to processes for what and how they should function. And the biggest driver of those directives is the construct known as annotations. Countless tools use annotations as their marching orders, from Helm to Vault to Ingress controllers. Being able to set this metadata in a standard and programmatic way is not only hugely helpful but also necessary in many cases. Kyverno has the ability to easily do so using mutation rules. It's fairly common to see use cases where, among other resources, Pods need to be annotated for a specific reason. Before tools like Kyverno, this was often implemented as a purpose-built annotation utility. Kyverno can replace those utilities through some pretty nifty functionality on top of just simple annotations.
In this scenario, let's say you had a mapping of metadata that needed to be applied. If a Pod comes in with a label of app=nginx you need to apply an annotation called foo with the value of stack. But if the value of that app label was mongo instead, that annotation value should be something different. You essentially need a lookup table to map value X onto value Y, and that's a tricky thing to solve. With Kyverno, not only can those bespoke annotation tools be replaced, but you can actually use native Kubernetes constructs like a ConfigMap to define that reference table and dynamically apply the corresponding value.
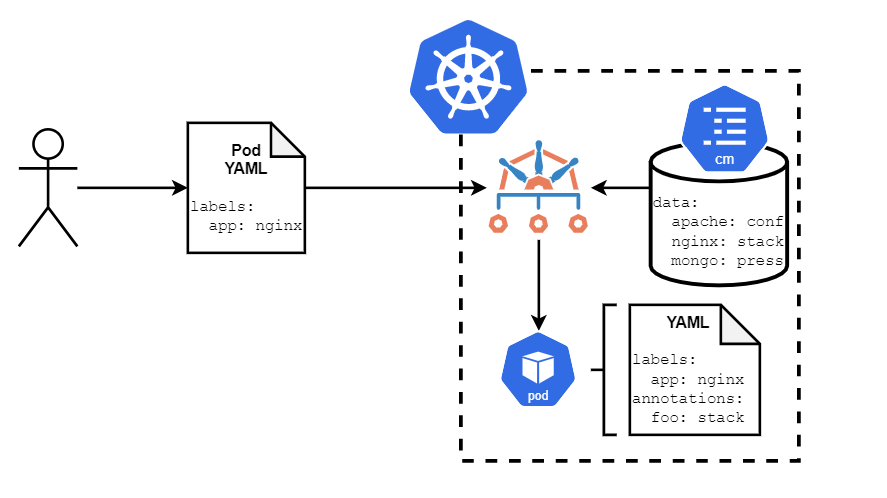
In order to implement this, we first need a ConfigMap that acts as our reference table. This is just your standard ConfigMap where each key has a corresponding value, forming the mapping between label and annotation.
TIP: You can expand each code block by clicking the dots at the bottom left, or using a nifty "expand" button in the floating tool panel in the upper right.
1apiVersion: v1
2kind: ConfigMap
3metadata:
4 name: resource-annotater-reference
5 namespace: default
6data:
7 apache: conf
8 nginx: stack
9 mongo: press
We now need a policy that contains the mutation logic. Below, I've written such a policy which does a couple things. First, it uses a concept called a context in Kyverno terms to provide a reference to an existing ConfigMap. Second, it uses JMESPath expressions (pronounced "James path"), one nested inside the other, in order to perform the reference and insertion of the value of annotation called foo.
1apiVersion: kyverno.io/v1
2kind: ClusterPolicy
3metadata:
4 name: resource-annotater
5spec:
6 background: false
7 rules:
8 - name: add-resource-annotations
9 context:
10 - name: LabelsCM
11 configMap:
12 name: resource-annotater-reference
13 namespace: default
14 preconditions:
15 - key: "{{request.object.metadata.labels.app}}"
16 operator: NotEquals
17 value: ""
18 - key: "{{request.operation}}"
19 operator: Equals
20 value: "CREATE"
21 match:
22 resources:
23 kinds:
24 - Pod
25 mutate:
26 overlay:
27 metadata:
28 annotations:
29 foo: "{{LabelsCM.data.{{ request.object.metadata.labels.app }}}}"
Finally, let's test with a simple Pod definition like the following one. In this definition, the input is the label named app with a value of nginx.
1apiVersion: v1
2kind: Pod
3metadata:
4 labels:
5 app: nginx
6 name: mypod
7spec:
8 automountServiceAccountToken: false
9 containers:
10 - name: busybox
11 image: busybox:1.28
12 args:
13 - "sleep"
14 - "9999"
After creating these three resources, check the annotations on your Pod and see that Kyverno wrote in the corresponding value found in the ConfigMap based upon the incoming value of the label app.
1$ kubectl get po mypod -o jsonpath='{.metadata.annotations}' | jq
2{
3 "foo": "stack",
4 "policies.kyverno.io/patches": "add-resource-annotations.resource-annotater.kyverno.io: removed /metadata/creationTimestamp\n"
5}
Awesome, there we go. Think how powerful this can be. Also, because Kyverno reads a ConfigMap only when a policy lookup is needed, that means you can use whatever tooling and techniques you currently use to manage and update them. Think about this use case when you need to maintain a list of billing codes or department IDs or customer prefixes, for example. There are a hundred or more possibilities where you can use this pattern to assign metadata to objects in Kubernetes based upon some sort of map or table like what I illustrated.
There's a known issue whereby preconditions aren't getting copied to higher-level controllers. So, for the time being, some modifications may be needed to the policy in order to work on, say, Deployments.
Secret Copier/Syncher
Kubernetes Secrets are widely used and often the source of many different types of important pieces of data ranging from credentials to certificates to younameit. Secrets are also namespaced resources, and therein often lies the problem. Extremely commonly, you need one or multiple Secrets to be available in multiple Namespaces. In addition, it's a common desire to keep those Secrets in sync so that if the upstream Secret changes (for example, if a certificate is renewed), those downstream Secrets are updated. For this, there are lots of little (and big) tools out there. And before Kyverno, you kinda needed them because it was (and is) a problem for which Kubernetes didn't have a native solution. But with Kyverno, that's just another tool you can do away with. So let's look at another common use case that Kyverno nicely solves: syncing Kubernetes Secrets.
One of the leading uses I continually see is the need to make registry pull credentials available. More recently, this was due to Docker Hub implementing rate limiting, but even when using third-party registries it is often necessary when pulling from confidential repositories. Whatever your case, image pull secrets are a common requirement in production environments. In this scenario, we'll assume that you, the cluster administrator or owner, need to make a single set of registry credentials available to all Namespaces in your cluster.
To start, we obviously need a Kubernetes Secret which stores our credentials. If you're not familiar with this process, this is a good place to start. I've got one just called "regcred" which I need to get copied to new Namespaces. Kyverno, furthering of its ability to function as a Swiss Army knife, has a unique ability to generate resources (even custom ones!). That same ability also extends to the copy functionality. So by using Kyverno, we can copy our "regcred" Secret from a source Namespace to any N number of destination Namespaces. Instead of copying, we could also generate that as a totally new resource (defined in the policy itself) instead if we chose, but let's go with copy here.
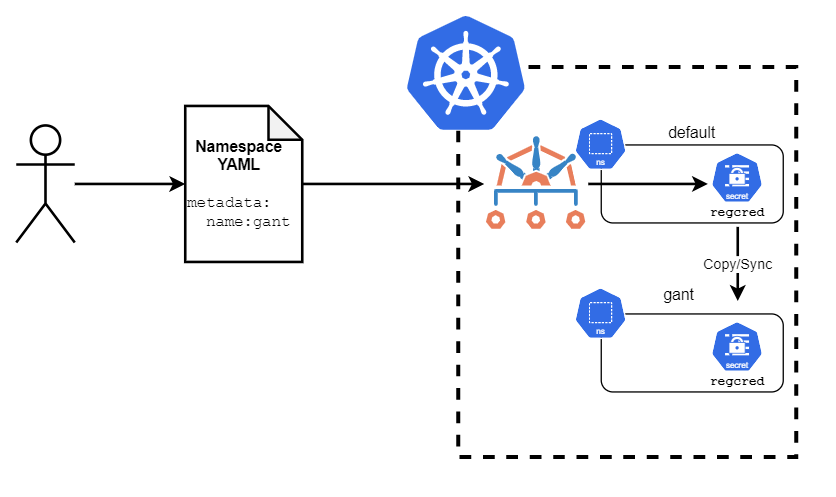
Once your Secret exists, we need a policy which contains the logic to tell Kyverno how and where to copy this. Here's a sample policy below which does the job.
1apiVersion: kyverno.io/v1
2kind: ClusterPolicy
3metadata:
4 name: sync-secret
5spec:
6 background: false
7 rules:
8 - name: sync-image-pull-secret
9 match:
10 resources:
11 kinds:
12 - Namespace
13 generate:
14 kind: Secret
15 name: regcred
16 namespace: "{{request.object.metadata.name}}"
17 synchronize: true
18 clone:
19 namespace: default
20 name: regcred
It's very straightforward: We take a Secret called regcred stored in the default Namespace and, any time a new Namespace is created, we instantly copy that Secret there. With synchronize: true, we ask Kyverno to watch over the source of the Secret and, should it change, to reflect those changes downstream. Pretty simple, but very powerful.
Create your new Namespace and check the result.
1$ kubectl create ns gant && kubectl get secret -n gant
2namespace/gant created
3NAME TYPE DATA AGE
4default-token-25gx9 kubernetes.io/service-account-token 3 0s
5regcred kubernetes.io/dockerconfigjson 1 0s
Since our Kyverno policy matches on all Namespaces, this Secret will get copied to every new one. Need to change the source Secret to store updated creds? Not a problem, just update it using whatever tools/processes you have and Kyverno will watch over and sync them up.
Sidecar Injector
In Cornelia Davis' brilliant book, Cloud Native Patterns (Manning, 2019), she describes Kubernetes sidecars simply as "a process that runs alongside your main service." No matter the higher-level purpose, whether that's API gateways or service meshes or logging agents, that is essentially all a sidecar is intended to do. There are, of course, many more practical use cases for sidecars, but whatever your application-specific use case, sidecars are commonplace.
In this use case, I want to demonstrate Kyverno's mutation ability to add a sidecar for the purposes of Hashicorp Vault integration. Now, I know I covered Secrets a bit in the above use case, but Vault is pretty common (and a great piece of tech, too), and so this is yet another opportunity where Kyverno can shine.
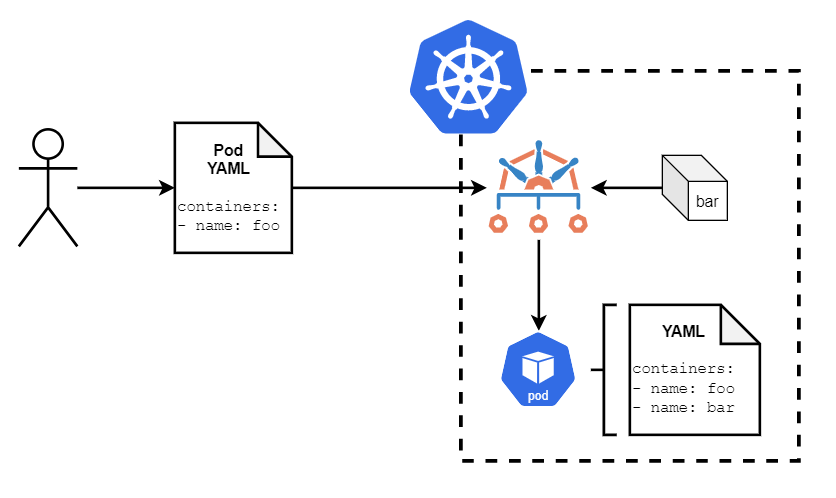
With Vault, the idea is to retrieve a Secret stored within an external Vault system for use by an application running inside a Kubernetes Pod. Rather that build the necessary logic in at the container level to do so, we want to decouple that logic so our app runs as it normally would, and a purpose-built process retrieves and makes available said Secret. The sidecar pattern is often employed for this use case, and so we can use Kyverno to inject the necessary sidecars at runtime to get the job done. The below policy is an example of how to take care of this.
1apiVersion: kyverno.io/v1
2kind: ClusterPolicy
3metadata:
4 name: inject-sidecar
5spec:
6 background: false
7 rules:
8 - name: inject-sidecar
9 match:
10 resources:
11 kinds:
12 - Deployment
13 mutate:
14 patchStrategicMerge:
15 spec:
16 template:
17 metadata:
18 annotations:
19 (vault.hashicorp.com/agent-inject): "true"
20 spec:
21 containers:
22 - name: vault-agent
23 image: vault:1.5.4
24 imagePullPolicy: IfNotPresent
25 volumeMounts:
26 - mountPath: /vault/secrets
27 name: vault-secret
28 initContainers:
29 - name: vault-agent-init
30 image: vault:1.5.4
31 imagePullPolicy: IfNotPresent
32 volumeMounts:
33 - mountPath: /vault/secrets
34 name: vault-secret
35 volumes:
36 - name: vault-secret
37 emptyDir:
38 medium: Memory
Just like with the Pod annotater use case earlier, we're similarly performing a mutation. Only this time, we're looking for an annotation rather than setting one. Here, Kyverno is searching for an annotation called vault.hashicorp.com/agent-inject: "true". If it finds a Pod with that annotation (it cannot exist as an annotation on the Deployment itself), it does three things:
- Creates an ephemeral volume.
- Creates an initContainer with the Vault agent.
- Creates a sidecar container and mounts the volume to both.
All that's left now is to create such a Deployment resource and see if Kyverno is mutating it.
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: kyvernodeploy
5 labels:
6 app: kyvernodeploy
7spec:
8 replicas: 1
9 selector:
10 matchLabels:
11 app: kyvernodeploy
12 template:
13 metadata:
14 labels:
15 app: kyvernodeploy
16 annotations:
17 vault.hashicorp.com/agent-inject: "true"
18 spec:
19 containers:
20 - name: busybox
21 image: busybox:1.28
22 imagePullPolicy: IfNotPresent
23 command: ["sleep", "9999"]
Create the Deployment and let's have a look.
1$ k get po
2NAME READY STATUS RESTARTS AGE
3kyvernodeploy-66494487f6-t2lvm 2/2 Running 0 2m19s
We can see from the above that, although our definition had but a single container, we're now running two. Further describing the Pod will show the second is the vault-agent container.
This is meant for illustration purposes. In actuality, you need more info in the policy than this. For more Vault-specific information, see their blog post.
Even though I showed this use case through integration with Hashicorp Vault, you can see there's nothing Vault specific in the policy precluding you from using it where/however you need in your environment. Whatever type of sidecar you need, Kyverno can inject it for you eliminating yet another tool in your box.
Resource Padlock
RBAC in Kubernetes is a great (and highly needed) thing. But RBAC has its limitations just like other security mechanisms. Kubernetes RBAC allows you to grant specific privileges in the form of verb, resource, and API group on a cluster-wide or per-Namespace basis. But the Namespace is as deep as RBAC goes. So, for example, you cannot create a RoleBinding which says, "give developers access to delete all Secrets in their Namespace except the one called 'super-secret-secret'." With RBAC, it's an all-or-nothing proposition at a resource level--you can either do it on all of them or none of them. This is where Kyverno can step in and help you by applying sub-RBAC permissions on a per-item level.
One such example of the need for sub-RBAC permissions I've seen is the ability to block updates and deletions on specific resources based on some criteria. This is generally desired to protect "system-level" components so, as with the Secret example above, a user cannot unknowingly (or perhaps maliciously) take out a TLS pair which renders apps insecure or wholesale broken. The other positive consequence such an ability brings is the ability to simplify Roles and ClusterRoles without having to make them messy and numerous. With Kyverno, you can do things like create those resource padlocks without having to resort to another tool and process. Let's see how this is handled.
I'm operating a production Kubernetes cluster in a semi-multi-tenant way in which there are multiple Namespaces with different groups of developers entitled to each one. A number of apps run across these Namespaces with some servicing internal customers and others for external customers, but they're mixed in these Namespaces. And, since many resources in Kubernetes are namespaced, they have to exist in one and only one Namespace. I want to keep my Roles in this cluster simple but block my developers (even those with admin privileges) from accidentally deleting external-facing resources, such as an Ingress rule.
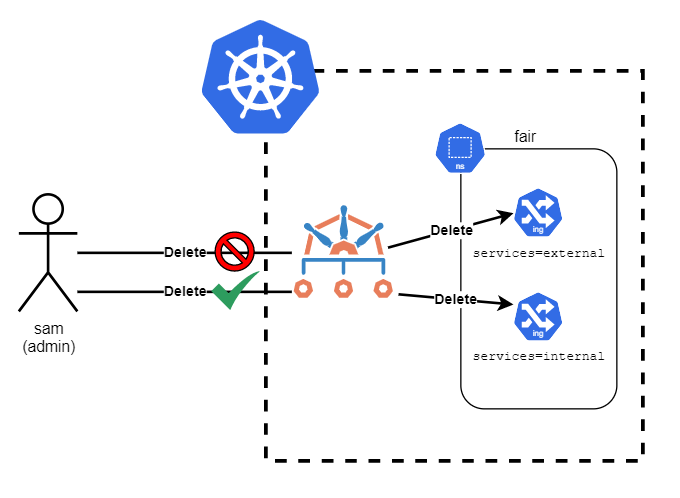
The components that collectively provide for this external customer access I have labeled with a special label called services=external. Wherever this label is applied, I want to block updates and deletes unless they come from someone with the cluster-admin role. With a policy like the below in place, I can now make that happen. All that needs to be done is assign the label services=external to an object.
1apiVersion: kyverno.io/v1
2kind: ClusterPolicy
3metadata:
4 name: block-updates-deletes
5spec:
6 validationFailureAction: enforce
7 background: false
8 rules:
9 - name: block-updates-deletes
10 match:
11 resources:
12 selector:
13 matchLabels:
14 services: external
15 exclude:
16 clusterRoles:
17 - cluster-admin
18 validate:
19 message: "Modifying or deleting the external customer resource {{request.oldObject.kind}}/{{request.oldObject.metadata.name}} is not allowed. Please seek a cluster-admin."
20 deny:
21 conditions:
22 - key: "{{request.operation}}"
23 operator: In
24 value:
25 - DELETE
26 - UPDATE
With the above policy created, let's see if Sam, an admin over the Namespace called fair, can delete an Ingress resource labeled with services=external. First, let's check and make sure, from a Kubernetes RBAC perspective, he does have the permission.
1$ kubectl -n fair auth can-i delete ing/external --as sam
2yes
So we know he has the privilege to do so. Let's now actually try to delete it.
1$ kubectl -n fair delete ing/external --as sam
2Warning: extensions/v1beta1 Ingress is deprecated in v1.14+, unavailable in v1.22+; use networking.k8s.io/v1 Ingress
3Error from server: admission webhook "validate.kyverno.svc" denied the request:
4
5resource Ingress/fair/external was blocked due to the following policies
6
7block-updates-deletes:
8 block-updates-deletes: Modifying or deleting the external customer resource Ingress/external is not allowed. Please seek a cluster-admin.
This is Kyverno, not Kubernetes, seeing Sam's delete request and, although he has permission at the Kubernetes level, he doesn't from Kyverno's. His request to delete is therefore blocked.
But he can still control resources that weren't padlocked, right?
1$ k -n fair delete ing/internal --as sam
2Warning: extensions/v1beta1 Ingress is deprecated in v1.14+, unavailable in v1.22+; use networking.k8s.io/v1 Ingress
3ingress.extensions "internal" deleted
And there you go. Sam ain't deleting that Ingress rule any time soon (but, sorry, internal customers).
As you can see, Kyverno can extend the RBAC capabilities of Kubernetes and apply to any resource you can label. In so doing, it gives you new found flexibility and also can eliminate yet another tool.
Namespace Provisioner
For the last use case, we come to the most complex (and most impressive) which lets us fully exploit all of Kyverno's cool abilities: Complete Namespace provisioning. Yes, you read that right. Kyverno can be the automation engine which delivers a fully-functional and provisioned Namespace based on your designs, even if they're very complex (like you'll see below). Although this is something more commonly seen in true multi-tenant environments, just about all clusters these days employ Namespaces for some type of segregation abilities. Whenever a new Namespace is created in Kubernetes, there are a number of things that follow-on which must be created for it to be useful. These are things like labels, RoleBindings, ResourceQuotas, maybe LimitRanges, etc. Maybe you have more requirements and maybe less. Whatever the case, you likely have some sort of runbook which codifies all the steps and resources that are required. There are many tools out there that can help with this, whether that be SaaS-based control planes or homegrown config management systems. Or maybe you've built this logic in your CD system. But this is yet another area where Kyverno can provide consolidation, standardization, and requires no coding to make work. And, like all things in Kyverno, everything is a Policy or ClusterPolicy, represented as a CustomResource, which means it can be stored in version control, deployed using GitOps, or any other methods you use today with standard Kubernetes resources.
Just consider a scenario like the following, illustrated in the below diagram, which represents a complex (but realistic) Namespace creation workflow in a production environment.
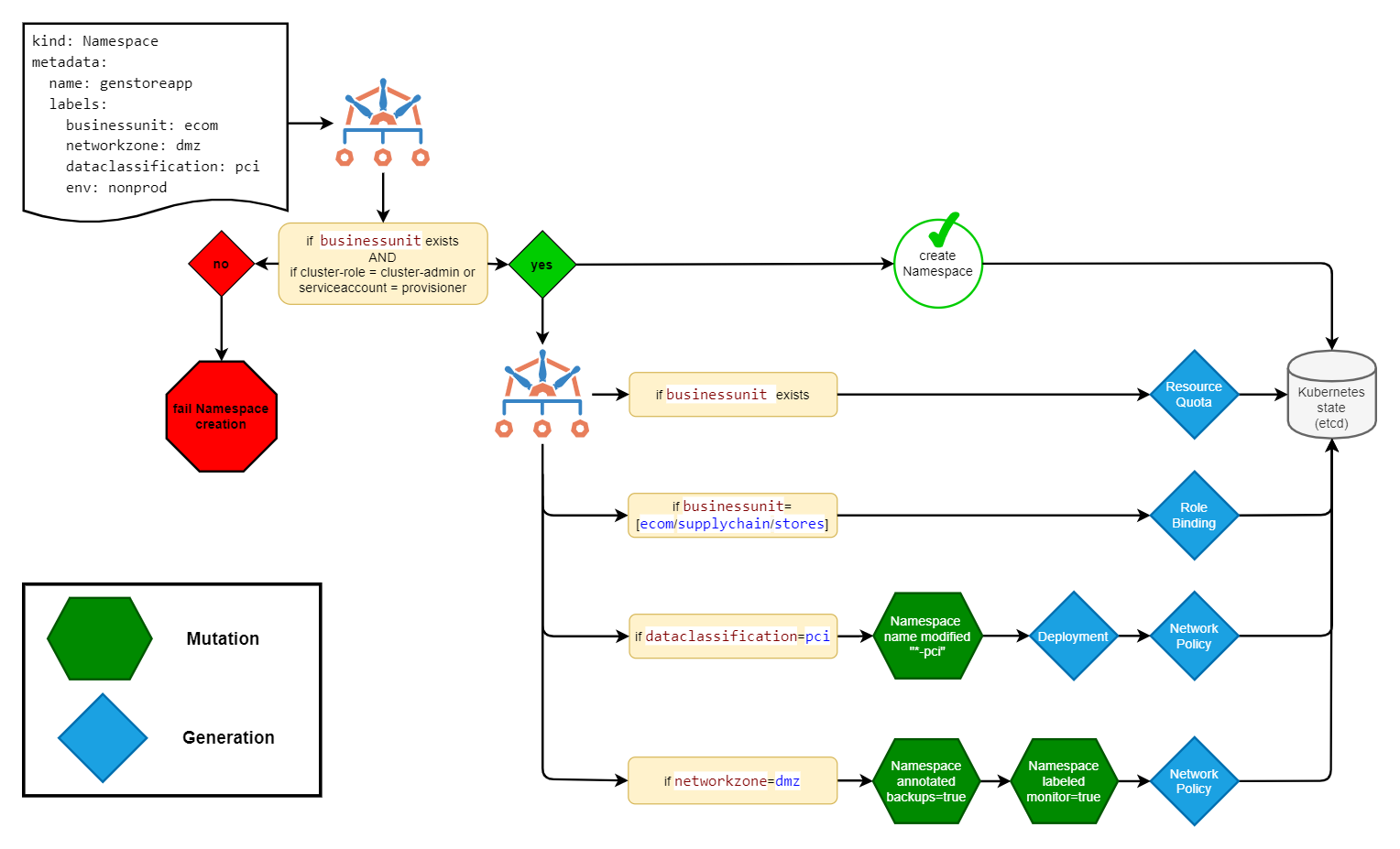
There's a lot going on here, so let's break it down:
- A new Namespace creation request comes in with a number of different labels assigned. Each label invokes some kind of action in Kyverno, often multiple. A label of
businessunitis first required, and Kyverno checks this exists and that the request came from an authorized user or service account. Although we might have many other users with permissions to create Namespaces, we don't want to trigger our provisioning workflow unless it comes from authorized users, which, in this case, is from someone holding thecluster-adminClusterRole or from a very specific service account. - Based upon the value of
businessunit, Kyverno will then generate a couple new resources as shown. - If the
dataclassificationlabel equals a defined value, we can manipulate the name of that Namespace and generate more items. Maybe, in this scenario, with it being classified aspci, you need a Deployment which applies some sort of introspection, monitoring, or logging application in order to meet those compliance requirements. - And, finally, if this Namespace is for a DMZ location, we can label and annotate the Namespace indicating it needs to be backed up and needs monitoring. Finally, it creates a specific NetworkPolicy which allows traffic only from other Pods which are pre-approved to communicate with the DMZ.
All these steps above are not mutually exclusive, and Kyverno can end up mutating/generating a union of some or all of them.
And, to finish it all off, here is a complete set of manifests that'll allow you to implement this complete diagram in your own environment.
First, you'll need to create some additional ClusterRoles and RoleBindings to give the Kyverno service account the necessary permissions it needs to generate some new resources. This is standard practice, especially when generating RoleBindings, so Kubernetes doesn't see a privilege escalation attempt.
1---
2# Needed for Kyverno to generate new Deployments
3apiVersion: rbac.authorization.k8s.io/v1
4kind: ClusterRole
5metadata:
6 name: kyverno:generate-deploy
7rules:
8- apiGroups:
9 - apps
10 resources:
11 - deployments
12 verbs:
13 - create
14 - get
15 - list
16 - patch
17 - update
18 - watch
19---
20# Needed for Kyverno to generate new Deployments using the custom ClusterRole called 'kyverno:generate-deploy'
21apiVersion: rbac.authorization.k8s.io/v1
22kind: ClusterRoleBinding
23metadata:
24 name: kyverno:generatecontroller-deployments
25roleRef:
26 apiGroup: rbac.authorization.k8s.io
27 kind: ClusterRole
28 name: kyverno:generate-deploy
29subjects:
30- kind: ServiceAccount
31 name: kyverno
32 namespace: kyverno
33---
34# Needed for Kyverno to generate new RoleBindings with the 'view' ClusterRole
35apiVersion: rbac.authorization.k8s.io/v1
36kind: ClusterRoleBinding
37metadata:
38 name: kyverno:generatecontroller-view
39roleRef:
40 apiGroup: rbac.authorization.k8s.io
41 kind: ClusterRole
42 name: view
43subjects:
44- kind: ServiceAccount
45 name: kyverno
46 namespace: kyverno
47---
48# Needed for Kyverno to generate roles and bindings (needed after Kyverno v1.3.3)
49apiVersion: rbac.authorization.k8s.io/v1
50kind: ClusterRole
51metadata:
52 name: kyverno:generatecontroller
53rules:
54- apiGroups:
55 - '*'
56 resources:
57 - namespaces
58 - networkpolicies
59 - secrets
60 - configmaps
61 - resourcequotas
62 - limitranges
63 - clusterroles
64 - rolebindings
65 - clusterrolebindings
66 verbs:
67 - create
68 - update
69 - delete
70 - list
71 - get
72- apiGroups:
73 - '*'
74 resources:
75 - namespaces
76 verbs:
77 - watch
And, finally, the complete ClusterPolicy to implement all rules as outlined in the diagram. Note the comments which explain what each rule is for.
1# Advanced Namespace provisioning workflow.
2# All Kyverno functionality is implemented in this policy
3# but as separate rules.
4apiVersion: kyverno.io/v1
5kind: ClusterPolicy
6metadata:
7 name: namespace-provisioning
8spec:
9 background: false
10 validationFailureAction: enforce
11 rules:
12 # Validate new Namespaces allow `businessunit` set by authorized roles
13 - name: restrict-labels-businessunit
14 match:
15 resources:
16 kinds:
17 - Namespace
18 exclude:
19 clusterRoles:
20 - cluster-admin
21 subjects:
22 - kind: ServiceAccount
23 name: nsprovisioner
24 namespace: kube-provisioner
25 validate:
26 message: "Only role=cluster-admin and kube-provisioner:nsprovisioner can set label `businessunit`."
27 pattern:
28 metadata:
29 =(labels):
30 X(businessunit): "null"
31 # Validate new Namespaces allow `dataclassification` set by authorized roles
32 - name: restrict-labels-dataclassification
33 match:
34 resources:
35 kinds:
36 - Namespace
37 exclude:
38 clusterRoles:
39 - cluster-admin
40 subjects:
41 - kind: ServiceAccount
42 name: nsprovisioner
43 namespace: kube-provisioner
44 validate:
45 message: "Only role=cluster-admin and kube-provisioner:nsprovisioner can set label `dataclassification`."
46 pattern:
47 metadata:
48 =(labels):
49 X(dataclassification): "null"
50 # Validate new Namespaces allow `networkzone` set by authorized roles
51 - name: restrict-labels-networkzone
52 match:
53 resources:
54 kinds:
55 - Namespace
56 exclude:
57 clusterRoles:
58 - cluster-admin
59 subjects:
60 - kind: ServiceAccount
61 name: nsprovisioner
62 namespace: kube-provisioner
63 validate:
64 message: "Only role=cluster-admin and kube-provisioner:nsprovisioner can set label `networkzone`."
65 pattern:
66 metadata:
67 =(labels):
68 X(networkzone): "null"
69 # generate default resourcequota when `businessunit` exists
70 - name: generate-resourcequota
71 match:
72 resources:
73 kinds:
74 - Namespace
75 preconditions:
76 - key: "{{request.object.metadata.labels.businessunit}}"
77 operator: NotEquals
78 value: ""
79 generate:
80 kind: ResourceQuota
81 name: default
82 namespace: "{{request.object.metadata.name}}"
83 synchronize: true
84 data:
85 spec:
86 hard:
87 cpu: "6"
88 memory: 12Gi
89 # generate default RoleBinding when `businessunit` equals predefined values
90 - name: generate-rolebinding
91 match:
92 resources:
93 kinds:
94 - Namespace
95 preconditions:
96 - key: "{{request.object.metadata.labels.businessunit}}"
97 operator: In
98 value: ["ecom","supplychain","stores"]
99 generate:
100 kind: RoleBinding
101 name: developer-viewer-binding
102 namespace: "{{request.object.metadata.name}}"
103 synchronize: true
104 data:
105 roleRef:
106 apiGroup: rbac.authorization.k8s.io
107 kind: ClusterRole
108 name: view
109 subjects:
110 - apiGroup: rbac.authorization.k8s.io
111 kind: Group
112 name: syd-devs
113 ### dataclassification=pci workflow branch
114 # Add `-pci` suffix to namespace when `dataclassification=pci` is set
115 - name: dataclassification-pci-mutate-ns
116 match:
117 resources:
118 kinds:
119 - Namespace
120 selector:
121 matchLabels:
122 dataclassification: pci
123 mutate:
124 patchStrategicMerge:
125 metadata:
126 name: "{{request.object.metadata.name}}-pci"
127 # Generate a new Deployment when `dataclassification=pci`.
128 - name: dataclassification-pci-generate-deploy
129 match:
130 resources:
131 kinds:
132 - Namespace
133 preconditions:
134 - key: "{{request.object.metadata.labels.dataclassification}}"
135 operator: Equals
136 value: pci
137 generate:
138 kind: Deployment
139 name: test-deploy
140 namespace: "{{request.object.metadata.name}}"
141 synchronize: false
142 data:
143 spec:
144 replicas: 1
145 selector:
146 matchLabels:
147 app: busybox
148 template:
149 metadata:
150 labels:
151 app: busybox
152 spec:
153 containers:
154 - name: busybox
155 image: busybox:1.28
156 command: ["sleep", "9999"]
157 resources:
158 requests:
159 memory: 100Mi
160 cpu: 100m
161 limits:
162 memory: 200Mi
163 # generate a default NetworkPolicy when `dataclassification=pci`
164 - name: dataclassification-pci-generate-netpol
165 match:
166 resources:
167 kinds:
168 - Namespace
169 preconditions:
170 - key: "{{request.object.metadata.labels.dataclassification}}"
171 operator: Equals
172 value: pci
173 generate:
174 kind: NetworkPolicy
175 name: basic-netpol
176 namespace: "{{request.object.metadata.name}}"
177 synchronize: true
178 data:
179 spec:
180 podSelector: {}
181 policyTypes:
182 - Ingress
183 - Egress
184 ### networkzone=dmz workflow branch
185 # annotate and label Namespace when `networkzone=dmz`
186 - name: networkzone-dmz-annotate-ns
187 match:
188 resources:
189 kinds:
190 - Namespace
191 selector:
192 matchLabels:
193 networkzone: dmz
194 mutate:
195 patchStrategicMerge:
196 metadata:
197 annotations:
198 label.corp.com/backups: "true"
199 labels:
200 monitor: "true"
201 # generate a new NetworkPolicy when `networkzone=dmz`
202 - name: networkzone-dmz-generate-netpol
203 match:
204 resources:
205 kinds:
206 - Namespace
207 preconditions:
208 - key: "{{request.object.metadata.labels.networkzone}}"
209 operator: Equals
210 value: dmz
211 generate:
212 kind: NetworkPolicy
213 name: dmz-netpol
214 namespace: "{{request.object.metadata.name}}"
215 synchronize: true
216 data:
217 spec:
218 podSelector:
219 matchLabels:
220 allowed-zone: dmz
221 policyTypes:
222 - Ingress
Wrap-Up
Alright, that was a lot! Even though this was a long article, I really and truly hope that I was able to get across now insanely useful Kyverno can be to you and your environments through illustration of these practical use cases; how easy and quickly it can serve in that regard; and how you can use this one tool to replace any number of other, specialized tools you might have scattered across your estate. If you found this useful, I'm always glad to hear it. If you thought it wasn't, I want to know that as well! Special thanks to Gregory May for allowing me to use his concept of the Namespace provisioning workflow and one of the rules.
Enjoy!